
Want smarter insights in your inbox? Sign up for our weekly newsletters to get only what matters to enterprise AI, data, and security leaders. Subscribe Now
A new study from Arizona State University researchers suggests that the celebrated “Chain-of-Thought” (CoT) reasoning in Large Language Models (LLMs) may be more of a “brittle mirage” than genuine intelligence. The research builds on a growing body of work questioning the depth of LLM reasoning, but it takes a unique “data distribution” lens to test where and why CoT breaks down systematically.
Crucially for application builders, the paper goes beyond critique to offer clear, practical guidance on how to account for these limitations when developing LLM-powered applications, from testing strategies to the role of fine-tuning.
The promise and problem of Chain-of-Thought
CoT prompting, which asks an LLM to “think step by step,” has shown impressive results on complex tasks, leading to the perception that models are engaging in human-like inferential processes. However, a closer inspection often reveals logical inconsistencies that challenge this view.
Various studies show that LLMs frequently rely on surface-level semantics and clues rather than logical procedures. The models generate plausible-sounding logic by repeating token patterns they have seen during training. Still, this approach often fails on tasks that deviate from familiar templates or when irrelevant information is introduced.
AI Scaling Hits Its Limits
Power caps, rising token costs, and inference delays are reshaping enterprise AI. Join our exclusive salon to discover how top teams are:
- Turning energy into a strategic advantage
- Architecting efficient inference for real throughput gains
- Unlocking competitive ROI with sustainable AI systems
Secure your spot to stay ahead: https://bit.ly/4mwGngO
Despite these observations, the researchers of the new study argue that “a systematic understanding of why and when CoT reasoning fails is still a mystery,” which their study aims to address. Previous work has already shown that LLMs struggle to generalize their reasoning abilities. As the paper notes, “theoretical and empirical evidence shows that CoT generalizes well only when test inputs share latent structures with training data; otherwise, performance declines sharply.”
A new lens on LLM reasoning
The ASU researchers propose a new lens to view this problem: CoT isn’t an act of reasoning but a sophisticated form of pattern matching, fundamentally bound by the statistical patterns in its training data. They posit that “CoT’s success stems not from a model’s inherent reasoning capacity, but from its ability to generalize conditionally to out-of-distribution (OOD) test cases that are structurally similar to in-distribution exemplars.” In other words, an LLM is good at applying old patterns to new data that looks similar, but not at solving truly novel problems.
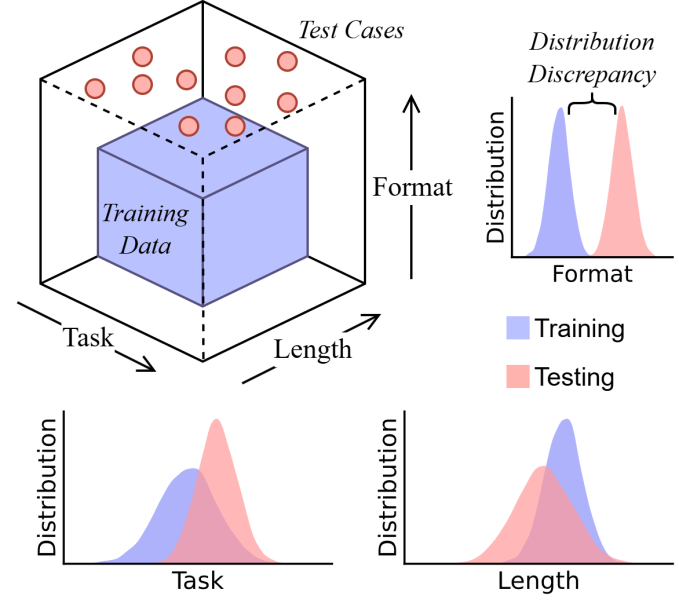
To test this hypothesis, they dissected CoT’s capabilities across three dimensions of “distributional shift” (changes between the training data and the test data). First, they tested “task generalization” to see if a model could apply a learned reasoning process to a new type of task. Second, they examined “length generalization” to determine if it could handle reasoning chains that are significantly longer or shorter than those it was trained on. Finally, they assessed “format generalization” to measure how sensitive the model is to minor changes in the prompt’s wording or structure.
For their analysis, they developed a framework called DataAlchemy to train smaller LLMs from scratch in a controlled environment, allowing them to precisely measure how performance degrades when pushed beyond the training data.
“The data distribution lens and controlled environment are both central to what we were trying to convey,” Chengshuai Zhao, doctoral student at ASU and co-author of the paper, told VentureBeat. “We hope to create a space where the public, researchers, and developers can freely explore and probe the nature of LLMs and advance the boundaries of human knowledge.”
The mirage confirmed
Based on their findings, the researchers conclude that CoT reasoning is a “sophisticated form of structured pattern matching, fundamentally bounded by the data distribution seen during training.” When tested even slightly outside this distribution, performance collapses. What looks like structured reasoning is more of a mirage, “emerging from memorized or interpolated patterns in the training data rather than logical inference.”
The breakdown was consistent across all three dimensions. On new tasks, models failed to generalize and instead replicated the closest patterns they had seen during training. When faced with reasoning chains of different lengths, they struggled, often trying to artificially add or remove steps to match the length of their training examples. Finally, their performance proved highly sensitive to superficial changes in the prompt, especially variations in core elements and instructions.
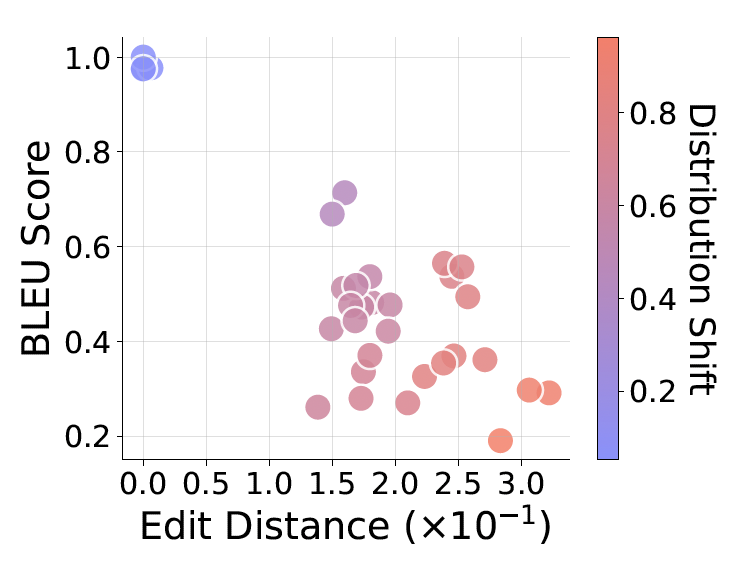
Interestingly, the researchers found that these failures could be quickly fixed. By fine-tuning the models on a very small sample of the new, unseen data through supervised fine-tuning (SFT), performance on that specific type of problem increased rapidly. However, this quick fix further supports the pattern-matching theory, suggesting the model isn’t learning to reason more abstractly but is instead just memorizing a new pattern to overcome a specific weakness.
Takeaways for the enterprise
The researchers offer a direct warning to practitioners, highlighting “the risk of relying on CoT as a plug-and-play solution for reasoning tasks and caution against equating CoT-style output with human thinking.” They provide three key pieces of advice for developers building applications with LLMs.
1)Guard against over-reliance and false confidence. CoT should not be treated as a reliable module for reasoning in high-stakes fields like finance or legal analysis. LLMs can produce “fluent nonsense” (plausible but logically flawed reasoning) that is more deceptive than an outright incorrect answer. The authors stress that “sufficient auditing from domain experts is indispensable.”
“The advance of science should remain human-centered—machines can assist, but discovery still thrives on humanity and curiosity,” Zhao said.
2) Prioritize out-of-distribution (OOD) testing. Standard validation, where test data mirrors training data, is not enough to measure true robustness. Developers must implement rigorous testing that systematically probes for failures across task, length, and format variations.
3)Recognize fine-tuning as a patch, not a panacea. While supervised fine-tuning (SFT) can quickly “patch” a model’s performance on a specific new data distribution, it does not create true generalization. It simply expands the model’s “in-distribution bubble” slightly. Relying on SFT to fix every OOD failure is an unsustainable strategy that fails to address the model’s core lack of abstract reasoning.
While CoT isn’t a form of human cognition, this limitation can be managed. Most enterprise applications involve a relatively narrow and predictable set of tasks. The paper’s findings provide a blueprint for ensuring reliability within these domains. Developers can build rigorous evaluation suites that systematically test model performance against the specific task, length, and format variations their application will encounter. This allows them to map out the boundaries of a model’s “in-distribution” comfort zone and identify where it aligns with their specific needs.
This targeted testing transforms fine-tuning from a reactive “patch” into a proactive strategy for alignment. When evaluations reveal a specific weakness, developers can create small, targeted SFT datasets to address it. Instead of trying to achieve broad, general reasoning, this approach uses SFT surgically to ensure the model’s pattern-matching capabilities are precisely aligned with the contours of a specific enterprise task. Ultimately, the study offers a practical lens for moving beyond hope and engineering LLM applications to achieve predictable success.

Source link
Disclaimer: This post is sourced from an external website via RSS feed. We do not claim ownership of the content and are not responsible for its accuracy or views. All rights belong to the original author or publisher. We are simply sharing it for informational purposes.